The purpose of this article is to provide guidance on how you can analyse the results when running the Cluster Optimizer within the DotActiv software.
The generated clusters grid is the first step in analysing clusters. You should first take note of the number of clusters it has suggested following by checking the number of stores it has put into each cluster, this eliminates the possibility of having a cluster for a small number of stores. We will then have a look at the store sizes within the clusters, this will help us assess the profiles of the store that ties in with the region.
The ability to see which stores in a specific region fall into a certain cluster, allows you to classify them as premium, mid-tier, economy or low-economy stores, and therefore cluster accordingly.
Lastly, the generated clusters grid also provides you with the NOD suggested per cluster, this allows you to pre-analyse the planograms you will need to build or assign to that specific cluster.
How To Analyse The Silhouette Coefficient
The silhouette coefficient is a method to help validate the consistency between clusters and how compact the clusters are. The graph is used to determine the number of clusters that will best suit the category, the range and shopping behaviour (buying more premium products or more economy within the category).
The score ranges between -1 and 1, where the optimum number of clusters is based on the horizontal bars, the bar closest to 1 is the most optimal.
A score of 1 means the clusters are separated from each other and have definite differences between the clusters.
A score of 0 or negative means the clusters are overlapping and there are similarities between the clusters with no distinct consumer preferences.
Sometimes the Cluster Optimizer gives a large number of clusters, for example, 20 with the optimal (closest to 1) being between 8-20. At DotActiv, the optimal number of clusters is 4 or less as it is not feasible to do clustering and ranging for 20 different clusters and the variants within the cluster. In this case, the user will run the Optimizer again. In the wizard at ‘Step 7’, select the ‘optimal cluster count’ and underneath add in the ‘Cap’ as 4. The Optimizer will work with the 4 as a maximum cap and a new silhouette coefficient graph is created. The graph will show the optimal clusters within the range of a maximum of 4.
It’s important to note that after this step it doesn’t mean the optimal clusters will be 4. The graph will show what the optimal number is between 1 and 4.
How To Analyse The Linkage Distance Metrics
The linkage distance determines the significance of the differences between the pre-determined clusters as established by the DotActiv software. DotActiv stipulates that the first sign of the need for clustering is that the Average metric has a greater than 16% difference. At DotActiv 16% is used because it is considered the point of significance and is where the clusters are diverse enough for clustering to be worth the client’s time and efforts.
Here you compare the various linkage distances between the cluster combinations and determine if there is a significant enough difference in order to recommend clustering. Comparisons between the suggested clusters can be made by selecting alternative clusters to compare from the drop-down list, for example, comparing clusters 1 and 2; 2 and 3; and 3 and 1. The various metrics will then be calculated by the software and will be displayed below the cluster comparisons.
Ensure you compare all the suggested clusters with one another as there may be instances where the percentage linkage distances might indicate that clusters are so similar that combining them might be more effective and efficient than attempting to separate them.
With these metrics, the software measures the physical distance between two stores (also called points) within the cluster being compared based on the type of metric used. The larger the percentage between clusters, the more significant the distance, and thus, the more diverse the clusters are, suggesting a greater need for clustering.
Let’s consider what each type of linkage distance metric measures.
- Single linkage distance
This is defined as the distance between the closest points in the two clusters being compared. Due to the fact that this metric compares the two closest points(stores) between clusters, one would expect that this metric has the smallest percentage compared to the other three. This is highlighted in the diagram below, where the single linkage distance is represented by the green arrow.
- Complete linkage distance
This is defined as the distance between the two most remote/outlier points (stores) among the two clusters being compared. Usually, one would expect this distance to be the greatest percentage difference in comparison to the other three metrics, as it equates to the furthest points. This is highlighted in the diagram below, where the complete linkage distance is represented by the red arrow.
- Average linkage distance
This is determined by taking the average of each cluster’s stores and comparing that to the average of another cluster’s stores – hence it is the average of the clusters being compared. This is highlighted in the diagram below, where the average linkage distance is represented by the blue arrow. We base the majority of the comparison on the average linkage distance as this provides an average across.
- Medoid linkage distance
This is determined as the central point of each cluster’s stores and is then compared with another cluster’s central point. This is highlighted in the diagram below, where the medoid linkage distance is represented by the orange arrow.

How To Analyse The Cluster Composition Scatter Graph
The scatter graph determines the significance of the differences between the pre-determined clusters as established by the DotActiv software. The Cluster Composition Scatter Graph provides a visual representation of the different stores on a graph based on the specific metrics chosen.
Here’s how a cluster composition scatter graph per store works:
Axes: The X and Y axes represent specific metrics related to the clusters in the store. These metrics could be things like sales at sell, sales at cost and other fact fields selected during the cluster optimization process.
Data Points: Each point on the scatter plot represents a specific store’s cluster, with its position based on the chosen metrics. For instance, if the X-axis is sales at sell and the Y-axis is profit, a point high on both axes would represent a store with high-value,and high profits.
Clusters: Different colours on the graph indicate different clusters. For example, cluster 1 would be green, and all the others would have a unique colour.
Insights: You can compare clusters across stores to see patterns. If certain clusters are consistently located in one area of the graph for certain stores, this could reveal insights into customer behaviour or store performance.
Trends: This type of graph can highlight outliers, trends, or gaps, helping identify stores where certain clusters outperform or underperform, allowing for targeted strategies to improve customer experience or sales in specific stores. For example, the stores were clustered in the image below according to region but as seen on the graph, stores in Cluster 2 (as shown in blue) and Cluster 3 (as shown in red) are performing similarly in relation to the fact fields chosen. This could be an indication that the stores grouped together should rather be clustered together to ensure the optimal clusters are selected for each store.
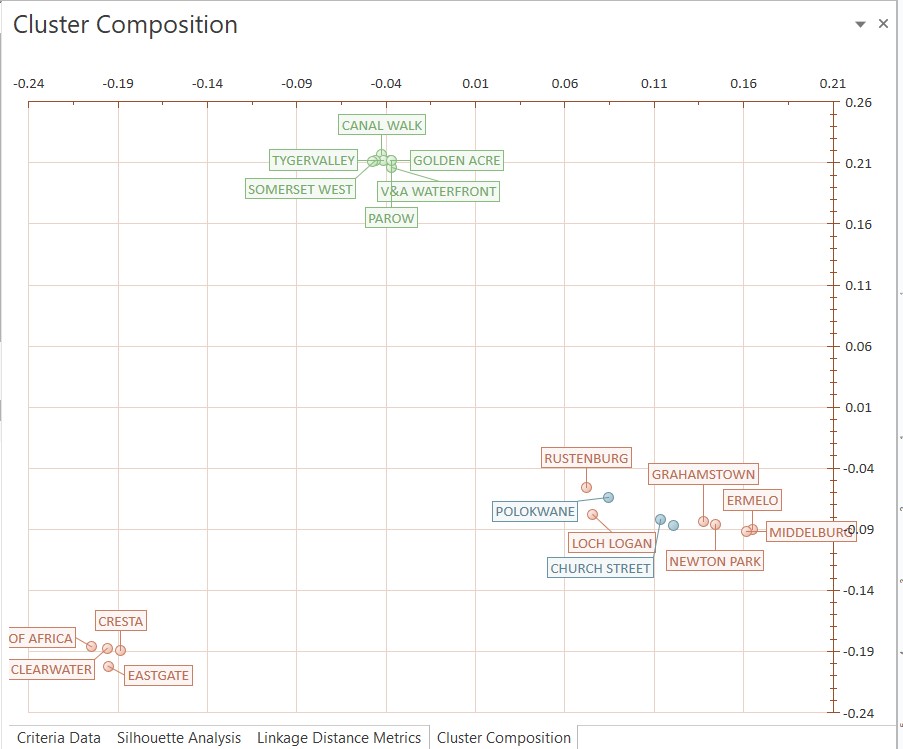
This approach allows for high-level visualization across multiple stores while revealing how different customer clusters behave within each store’s context.
How To Analyse Customer Preferences Using The Composition Changes Report
Average RSP – This gives you an idea of what the customer will be paying in-store as well as the LSM of the cluster. This is looked at, at a cluster, category, brand and sub-category level. Down the line, this will also assist with the range of each cluster.
Sales at Sell (Current and New) – This should give the user an idea of what subcategories or brands in each cluster are generating profit currently and will be to come. Sales Quantity should also be taken into consideration to identify subcategories and brands that may have been on promotion.
How To Analyse Cluster Profiling Using The Composition Changes Report
Average RSP (Current and New) – Use this data to determine the LSM of the stores in the suggested cluster. Based on the other cluster suggestions, you should be able to determine which clusters are Premium, Mid Tier and Economy. A higher average RSP would suggest that consumers are willing to spend more and thus indicate a Mid-Tier or Premium store.
Profit (Current and New) – Based on the “new” and “current” Profit data, you will be better equipped to make decisions based on profiling. Clusters with a higher RSP tend to generate more profit. This is not always the case and you need to take every field listed into account to get a bigger picture.
Sales at Sell (Current and New) – Sales at Sell indicate the sum of the amount of money spent. This also gives an indication that there will be an improvement once clustering is done.
In terms of profiling clusters with higher sales tend to be Mid-tier to Premium because they carry a more expensive range than that of an Economy cluster.
Sales Quantity (Current and New) – This ties in with Sales at Sell and is mostly used hand in hand with Sales at Sell. Low sales quantity but high Sales at Sell indicate that products sold have a high price and you can then interpret this as a premium cluster. It is also important to use the Average RSP as a guideline to confirm this.
It is important to note that if data looks skewed to ensure that promotions or markdown prices have not affected your data.
How To Save The Cluster Plan
If you’d like to know more about how you can save your cluster plan, read this article linked here.
How To Analyse The Impact Via The Cluster ADDM And Clusters Changes Report
The first part of the analysis starts on ‘Page 7’, which is the Store Composition Per Cluster. Here you can see the percentage of stores that make up all the clusters. This is the first graph that can tell you whether you should cluster or not. If you see that there is one specific cluster that makes up most of the stores, it might indicate that clustering isn’t necessary. If there is a more evenly split of the stores between clusters, that indicates a stronger reason to cluster. This shouldn’t be the only graph you take into consideration when deciding whether to cluster or not, but it is a good starting point.
When looking at ‘Page 9’ (Sales Display Hierarchy Contribution per Cluster), indicates which clusters spend more money on specific subcategories. This can indicate whether the clusters have different spending habits, or not. You can click on a specific subcategory to drill into it and gain more information on spending habits on the segment level.
If the sub-category level didn’t show clear differences between the clusters, drilling into the segment level might show you the differences. You can then drill further into a segment to see how every brand in that segment performs in your different clusters. If you are clustering based on LSM, this is where your clusters will start showing more differences as some brands are more popular among premium clusters, and some brands are more popular among economy clusters. This graph is very useful in determining what your specific clusters like spending their money on and if there are any specific trends.
When looking at ‘Page 10’ (Units Display Hierarchy Contribution per Cluster), you can determine how your different clusters shop in terms of the quantities they buy. As with the previous page, you can drill into the different subcategories to see the difference in units purchased in your different clusters and see if there are any trends. This is more likely to be evenly spread if you cluster based on LSM, and more likely to be different if you cluster based on Store Size. Clusters based on LSM focus on the brand profile and price of segments, whereas clusters based on Store Size focus on having more SKUs per segment because their consumers buy more of it.
If you cluster based on LSM, ‘Page 12’ (Store Profile Composition per Cluster) will be a very useful graph in determining clustering. This graph indicates which stores (based on profile) fall in your specific clusters and if there is a clear difference in-store profile among clusters. This is such an important graph because it can assist you in deciding to cluster a category where the Average Linkage isn’t very high, but you can clearly see a difference in consumer habits based on store profile. On the other side, if there isn’t a clear difference between store profiles it might assist you in deciding not to cluster.
Lastly, ‘Page 13’ (Brand Profile Composition per Cluster) will assist you in analysing the different brand profiles in each cluster. Like the previous graph, this is a useful graph to use in determining what your clusters prefer. If you drill into every brand profile, you will be able to see what brands form part of this specific brand profile, and how much each cluster prefers this brand. You can analyse the sales, quantity and gross profit of every brand in each cluster. This graph will also be important when you get to ranging, as it will assist you in seeing if you should remove brands from a specific range in a specific cluster.
After analysing all the graphs mentioned above, along with the Silhouette Coefficient and Linkage Distance, you should be able to determine if it is necessary to cluster a category, or not.
ADDM Report
ADDM stands for the additional demand expected from adding to the current assortment. The ADDM report focuses on the financial impact of the changes made from a DC and store level. Here you will be able to see the stock on hand at the DC, Store, the implications on the Goods in Transit (GIT), and the MDQ (minimum display quantities). The ADDM Report is divided vertically by store code due to the financial impact affecting the store directly – based on store size and SOH. The report also has three headings running horizontally across the top. The information presented is only for the products added or removed, not the whole range.
*Please also note that there are some prerequisites for this ADDM report to function as intended.
- Clustering in DotActiv software (requisite)
- Two planograms with differences in range and/or facings (to measure the financial impact accurately)
- The naming convention of planograms (in alignment with how they are classified and clustered in the database)
The following fields are required for the ADDM report to run optimally:
- Product Identification
- Minimum Display Depth (MDD) – this is typically represented by the number 1. However, for different environments, the MDD may differ as case packs may be a requirement of the account.
- Clustering set up for planogram or at least one store linked to the planogram
- Pack Sizes – account specific
- Selling Price (for calculating ADDM and RDDM at sell)
- MAC, which stands for Minimum Average Cost (for calculating ADDM / RDDM at cost).
Should one of these fields not be available, it will pull the missing column as “0” to indicate the missing information, however, pack size is not negotiable.
*This report will not be toggleable between clusters as it is intended to show the overall impact on the business based on the suggested range changes.